
안녕하세요. 이번 글쓰기에서는 트렌비의 카탈로그 조회 성능 최적화 이슈를 해결과정을 공유하는 글을 작성하고자 합니다.
배경
트렌비의 카탈로그 도메인의 프로젝트는 다음과 같은 기술 스택을 기반으로 개발되었습니다.
- Kotlin + Spring Boot 2.7.6
- QueryDSL 5.0.0
- Hibernate 5.6.14
- PostgreSQL 14.3
문제상황
트렌비에서는 2024년 2분기에 상품에 대한 카탈로그를 더 많이 생성하고, 많이 묶어 바로 시세를 제공하여 고객들에게 정확한 가격 비교와 바로 시세 데이터를 제공하고자 하는 목적이 있었습니다. 그 과정에서 카탈로그의 수가 증가하게 되었고 어느 순간 카탈로그 어드민 페이지가 전반적으로 성능이 떨어지는 모습을 볼 수 있었고 운영 쪽에서도 많은 인입이 들어왔습니다.
성능이 병목이 일어날 수 있는 부분을 찾아봤고, 해당 코드는 다음과 같습니다:
builder.and(
Expressions.booleanTemplate(
"ARRAYOVERLAP({0}, {1}) = true",
entity.goodsnos,
TypedParameterValue(LongArrayType.INSTANCE, goodsnos.toTypedArray())
)
)트렌비의 상품 번호를 관리하고 있는 데이터 컬럼은 bigint[] 컬럼입니다. PostgreSQL에서는 Array Function으로 아래 사진과 같은 연산자들을 제공해주고 있습니다.

위에 적혀있는 ARRAYOVERLAP Function은 && 연산자와 같으며, 이는 첫 번째 배열 요소에 두 번째 배열의 공통된 배열 요소가 있는지를 물어보는 연산자입니다. 실제로도 해당 쿼리는 문제없이 동작하고 있었습니다만, 왜 쿼리 지연이 발생한 걸까요?
PostgreSQL에서 해당 쿼리를 직접 수행해봤습니다.
EXPLAIN ANALYZE
SELECT *
FROM tables
WHERE goodsnos && ARRAY[1, 2, 3, 4, 5]::BIGINT[];
-- 예시 번호 입니다.
EXPLAIN은 실행 계획으로 어떤 쿼리가 실행되는지 알 수 있지만, 실행 전에 추측이기에 정확하지 않을 수 있기에 EXPLAIN ANALYZE를 사용하였습니다. 둘의 차이는 아래 블로그에 이해하기 쉽게 설명이 되어있으니 참고하시면 좋을 것 같습니다.
MySQL :: 슬로우쿼리 잡는 명령어, ‘EXPLAIN ANALYZE’ 해석법
쿼리가 왜 느린지 모르겠다면
velog.io
실제로도 인덱스를 태우고 있고, 조회 시에도 성능이 떨어지지 않는데 왜 슬로우 쿼리가 발생한 것일까요? 실제로 show_sql을 통한 로그로 어떤 쿼리가 나가고 있는지를 확인해봤습니다.

실제로 확인해보니, && 연산자가 아닌 ARRAYOVERLAP 함수로 조회가 이루어지고 있네요. 혹시 해당 함수가 index를 타지 않는 걸까? 하여 쿼리를 작성해봤습니다.

인덱스를 태우지 않고, 조회가 이루어지는 것을 확인 할 수 있었습니다. 거의 조회 속도가 거의 290배 정도 느려진 것을 볼 수 있습니다.
이제 문제를 알았으니, 성능 개선을 시작해보겠습니다.
해결 방안
먼저, 바로 떠오르는 방법으로 QueryDSL 코드에서 && 연산자를 사용하면 되지 않을까? 하여 다음과 같이 작성해봤습니다.
builder.and(
Expressions.booleanTemplate(
"{0} && {1}",
entity.goodsnos,
TypedParameterValue(LongArrayType.INSTANCE, entity.goodsnos.toTypedArray())
)
)
에러가 발생하였습니다.
&& 연산자를 처리하는 쿼리가 Hibernate의 Dialect에 등록이 되어있지 않은가봅니다. 정말 그러한가 하여 QueryDSL의 PostgreSQL Dialect를 확인해봤으나, &&, @> 등 ARRAY 연산자를 사용하는 쿼리는 별도로 보이지 않았습니다.
그럼 이제 두 개의 방법을 살펴봅시다.
방안 1. NativeQuery 사용하기
Array 연산자들에 대한 쿼리를 생성해주지 않으니 가장 먼저 떠올릴 수 있는 부분은 NativeQuery를 작성하는 부분 일 것입니다.
실제로 조회를 하는데 있어서 조건이 복잡하지 않으면 가장 먼저 해당 방법을 사용 할 수 있을 것이고, 실제로 goodsno 만 조회하는 부분을 NativeQuery로 아래와 같이 작성하여 조회해보겠습니다.
entityManager.createNativeQuery(
"SELECT * FROM table WHERE goodsnos && CAST(:goodsnos AS bigint[])
Entity::class.java
)
.setParameter("goodsnos", goodsnos.joinToString(",", "{", "}"))
.resultList as List<Entity>
&& 연산자 사용이 문제 없이 이루어지는 것을 볼 수 있습니다. 하지만, 문제는 동적 쿼리를 작성해야 되는 부분의 쿼리를 수정을 했었어야 했는데요. 카탈로그의 동적 조회 쿼리 조회 시 조건이 상당히 많기에 이를 전부 NativeQuery로 옮긴다면 적지 않은 리소스를 사용해야 했습니다.
방안 2. Dialect 상속하여 CustomFunction 등록하기
&& 연산자를 Hibernate에서 제공해주지 않는다면, 직접 만들어서 사용하면 되지 않을까? 란 생각이 들었고 시도해봤습니다.
먼저, 기존에는 PostgreSQL95Dialect 를 사용 중 이었습니다.
따라서, 해당 Dialect를 상속하여 몇 개의 Function을 추가하도록 하였습니다.
class CustomPostgreSQLDialect : PostgreSQL95Dialect() {
init {
registerFunction("overlap", OverlapSQLFunction())
registerFunction("contains", ContainsSQLFunction())
}
class OverlapSQLFunction : SQLFunction {
override fun getReturnType(firstArgumentType: Type?, mapping: Mapping): Type {
return BooleanType.INSTANCE
}
override fun render(firstArgumentType: Type?, arguments: MutableList<Any?>?, factory: SessionFactoryImplementor?): String {
if (arguments?.size != 2) {
throw IllegalArgumentException("The function must be passed 2 arguments")
}
return "${arguments[0]} && ${arguments[1]}"
}
override fun hasArguments(): Boolean {
return true
}
override fun hasParenthesesIfNoArguments(): Boolean {
return true
}
}
class ContainsSQLFunction : SQLFunction {
override fun getReturnType(firstArgumentType: Type?, mapping: Mapping): Type {
return BooleanType.INSTANCE
}
override fun render(firstArgumentType: Type?, arguments: MutableList<Any?>?, factory: SessionFactoryImplementor?): String {
if (arguments?.size != 2) {
throw IllegalArgumentException("The function must be passed 2 arguments")
}
return "${arguments[0]} @> ${arguments[1]}"
}
override fun hasArguments(): Boolean {
return true
}
override fun hasParenthesesIfNoArguments(): Boolean {
return true
}
}
}
Overlap, Contains 두 개를 만들어 주었습니다. 기존에 존재하던 StandardFunction 이라면 name으로 아래의 예시 코드와 같이 가능하지만, function 자체로는 인덱스가 타지 않는 것을 봤으니 직접 만들어주었습니다.
public PostgreSQL94Dialect() {
super();
registerFunction( "make_interval", new StandardSQLFunction("make_interval", StandardBasicTypes.TIMESTAMP) );
registerFunction( "make_timestamp", new StandardSQLFunction("make_timestamp", StandardBasicTypes.TIMESTAMP) );
registerFunction( "make_timestamptz", new StandardSQLFunction("make_timestamptz", StandardBasicTypes.TIMESTAMP) );
registerFunction( "make_date", new StandardSQLFunction("make_date", StandardBasicTypes.DATE) );
registerFunction( "make_time", new StandardSQLFunction("make_time", StandardBasicTypes.TIME) );
}
마지막으로 Dialect를 Customizing 했으니 실제 Hibernate.dialect도 변경해주도록 합니다.
spring:
jpa:
database-platform: database-platform: entity.configure.jpa.CustomPostgreSQLDialect결과
다시 한 번, 변경된 Dialect로 조회 쿼리를 호출해본 결과 다음과 같은 결과를 얻을 수 있었습니다.
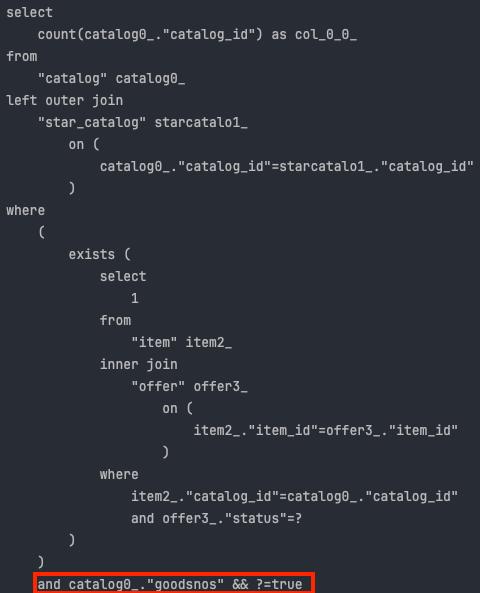
&& 연산자로 정상적으로 쿼리를 렌더링해서 조회가 되고 있는 것을 확인해 볼 수 있습니다.
실제로 해당 배포 이후에 카탈로그 어드민을 이용하시는 많은 운영분들께서 작업을 하시는데 불편함이 많이 개선되었습니다.
결론
2분기 카탈로그 생성 및 매칭에 초점을 맞추어 작업을 진행하였지만 나타났던 부수적인 상황에서 Dialect를 커스텀하여 문제를 해결하였습니다. 실제로 해당 문제를 개선하는 과정에서 많은 부분을 깨달을 수 있었습니다. 전반적으로는 다음과 같은 사고가 머리에 자리잡히게 된 계기였습니다.
"세상에 어차피 모든 것은 코드로 이루어져있어. 인터페이스를 이해하고 잘 만들어내기만 한다면 뭐든 만들어 낼 수 있을거야."
현실은 쉽지 않기는 하지만 약간의 두려움이라는 벽을 조금 허무는 듯한 경험을 얻게 되어 굉장히 뿌듯한 성과였습니다.
PostgreSQL을 사용하면서 배열 연산자로 고통 받는 분들에게 조금이나마 도움이 되었으면 합니다.
감사합니다.