
영속성 컨텍스트란?
영속성 컨텍스트란 엔티티를 영구 저장하는 환경을 의미하고, 애플리케이션과 DB 사이에서 캐시를 이용해 데이터를 보관하는 역할을 한다.
이때 영속성 컨텍스트는 엔티티 매니저를 통해서만 접근이 가능하다.
영속성 컨텍스트에 데이터를 저장하기 위해서는 다음과 같이 저장할 수 있다.
EntityManager em = emf.createEntityManager();
em.persist(entity);영속성 컨텍스트는 환경에 따라 달리 구성될 수 있다.
스프링 같은 멀티 쓰레드 환경에서는 EntityManager : PersistenceContext 관계는 N : 1 관계이고, 단일 쓰레드 환경에서는 1 : 1 관계이다.
이어서 영속성 컨텍스트 내부에서 엔티티의 생명주기에 대해서 살펴보자.
영속성 컨텍스트 내부 엔티티의 생명주기
- 비영속(new/transient) : 영속성 컨텍스트와 전혀 관련이 없는 상태이다.
- 영속(managed) : 영속성 컨텍스트가 엔티티를 관리하는 상태이다.
- 준영속(detached) : 영속성 컨텍스트에 있던 엔티티가 분리된 상태이다. 즉, 영속성 컨텍스트에서 해당 엔티티를 찾을 수 없다.
- 삭제(removed) : 삭제된 상태이다.

이어서 영속성 컨텍스트의 특징과 그 장점에 대해서 살펴보자.
영속성 컨텍스트의 특징
영속성 컨텍스트는 엔티티를 식별자 값으로 구분을 한다. 따라서 영속 상태에 있다면 반드시 식별 값이 있어야 하는데, 이에 따라 기본키 생성 단계에서 영속성 컨텍스트가 예외적으로 동작하는 경우들이 있다.
그럼 영속성 컨텍스트의 장점은 무엇일까 이는 다음과 같다.
- 1차 캐시
- 동일성 보장(identity)
- 트랜잭션을 지원하는 쓰기 지연(behind-write)
- 변경 감지(dirty-checking)
- 지연 로딩(lazy-loading)
각각이 무엇을 의미하는지 하나 하나 살펴보자.
1차 캐시
JPA는 영속성 컨텍스트를 1차 캐시로 이용을 한다. 이에 따라 DB에서 조회 할 때의 흐름이 조금 다르다.
em.persist(entity);
em.find(Entity.class, entity.getId());
// id 는 기본 키다음과 같은 상황을 생각해보자. 일반적으로 JPA를 다뤄보지 않은 개발자라면 다음과 같은 상황을 생각 할 것이다.
Insert into Entity values(...);
Select * from Entity where id = ...;하지만 실제로 발생하는 쿼리를 로그로 찍어보면 그 어디에도 삽입과 조회를 한 쿼리를 볼 수 없다.
그리고 DB를 확인해봐도 값을 확인 할 수 없다.
JPA가 영속성 컨텍스트를 1차 캐시로 사용하기 때문에 발생한 일이다.
영속성 컨텍스트 내부에서는 쓰기 지연 SQL 저장소가 따로 존재한다. 여기서 JPA의 가장 큰 특징은 무조~건 한 트랜잭션 안에서 동작한다는 것이다. 즉, 커밋을 해주지 않으면 DB에 반영 자체가 안된다.

따라서 위에 코드를 보면 commit 을 해주지 않았기 떄문에, 영속성 컨텍스트라는 1차 캐시에 Entity가 보관되어 있고, 쓰기 지연 SQL 저장소에서 DB에 데이터를 전송하기를 기다리는 상태이기 떄문에 DB에 쿼리를 날리지 않은 것이다.
영속성 컨텍스트의 쓰기 지연 SQL 저장소에 있는 쿼리를 DB에 전송하는 방법은 여러가지가 있다.
1. em.flush()
2. 트랜잭션 커밋
3. JPQL 쿼리 실행(단, em.setFlushMode 옵션이 AUTO일 경우)
이어서 1차 캐시로 인한 조회 할 때의 JPA의 흐름을 살펴보자.
- 먼저 영속성 컨텍스트의 1차 캐시에서 엔티티를 찾는다.
- 없으면 데이터베이스에서 조회한다.
- 조회한 데이터를 엔티티로 생성해 영속성 컨텍스트의 1차 캐시에 저장한다.
- 조회한 엔티티를 반환한다.
만약 1번에서 조회가 됐다면 바로 4번으로 넘어가는 것이다.
동일성 보장
동일성이란 객체의 상태가 다르더라도 식별자가 같으면 동일한 객체로 간주하는 것이다.
JPA는 이러한 동일성을 보장을 해준다.
Entity e1 = em.find(Entity.class, 1L);
Entity e2 = em.find(Entity.class, 1L);
log.info(e1 == e2); // true쓰기 지연
쓰기 지연은 영속성 컨텍스트의 쓰기 지연 SQL 저장소에 쿼리를 모아두었다가 어느 조건이 달성하여 DB에 쿼리가 전송되는 것을 말한다.
마치 쿼리를 쌓아두었다가 실행하는 배치와 비슷한 개념이다.
EntityTransaction tx = em.getTransaction();
Entity e1 = new Entity();
Entity e2 = new Entity();
Entity e3 = new Entity();
tx.begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
// 아직까지 Insert Query 발생 X
// 1. tx.commit();
// 2. em.flush();
// 3. jpql 쿼리 실행;
// 위 3가지 수행 시 모두 저장 된 쿼리 수행되게 간편해보이기도 하고 엄청난 성능 향상이 될 것으로 기대되지만, 생각보다 눈에 띄는 성능 향상이 없다고 한다.
그리고 1차 캐시에 대해서도 실제로 트랜잭션 단위로 수행되고 commit이 된다면 영속성 컨텍스트를 비우기 때문에 캐시 성능에 대해서 많은 성능 향상을 기대하기 어렵다.
변경 감지
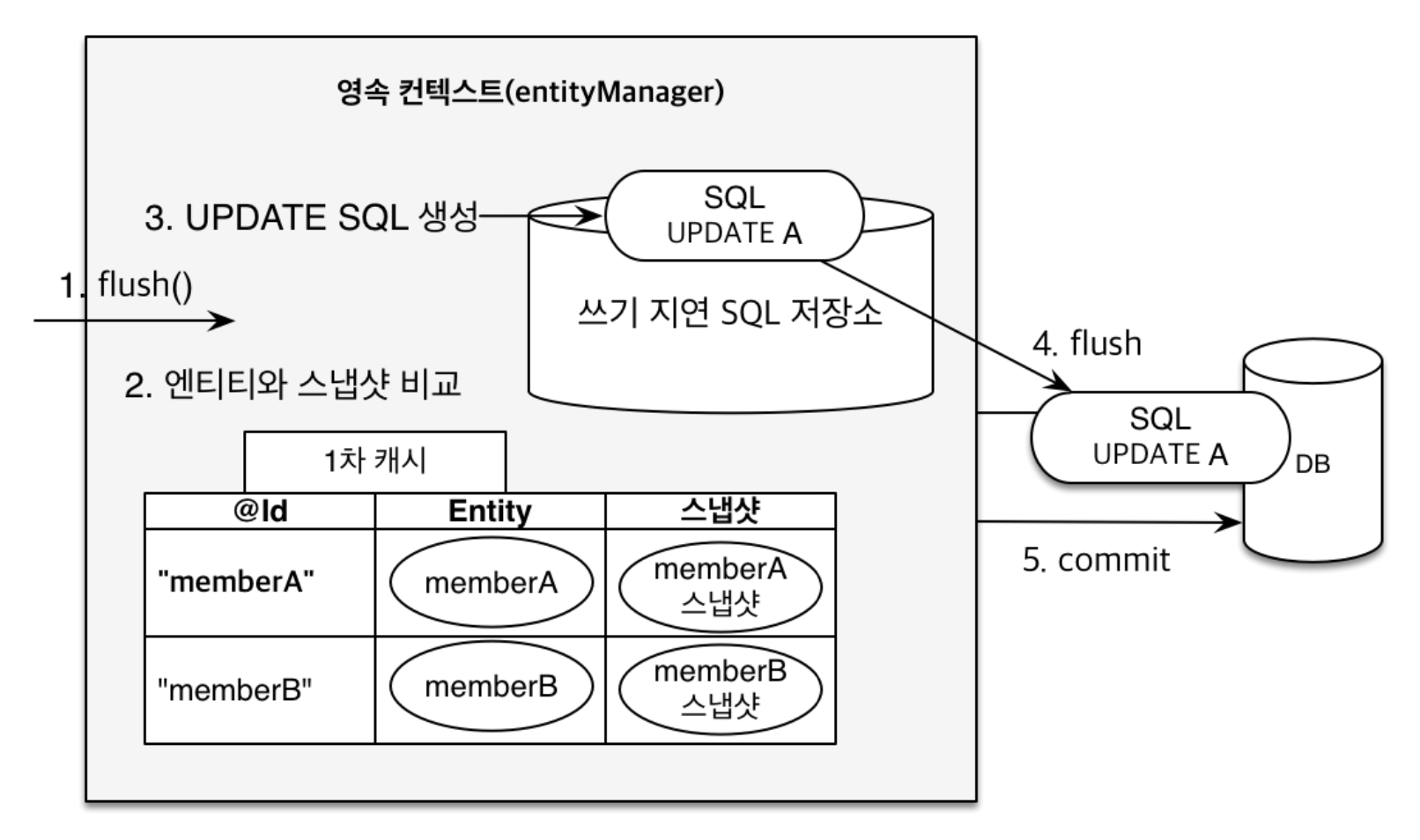
변경 감지는 업데이트 시 많이 활용된다. 아까 위에서 봤던 영속성 컨텍스트를 다시 살펴보면 식별자와 엔티티 객체밖에 보이지 않은 것을 알 수 있는데, 실제로는 저거 말고도 스냅샷이 존재한다.
JPA는 스냅샷과 현재 객체의 상태가 동일하지 않으면 쓰지 지연 저장소로 보내고 자동적으로 업데이트를 수행하게 해준다.
뭔가 느낌이 오지 않는가. 이는 마치 캐시가 동작하는 원리와 비슷하다.
업데이트를 하기 위해서 기존의 Mapper를 사용했거나 DB를 사용했다면 다음처럼 예상 할 것이다.
em.update(entity);하지만 해당 메서드는 존재하지 않는다. 위의 스냅샷을 이용해 비교 할 때는 다음과 같이 하더라도 변경이 된다.
Entity e = em.find(Entity.class, 1L);
e.setName("변경");기존의 Entity 객체의 name 필드가 변경이 아니였다면 영속성 컨텍스트에서 스냅샷과 현재 엔티티의 상태를 비교하고, 다르다면 쓰기 지연 저장소로 보내서 Update 쿼리가 호출되도록 한다. 정리하면 다음과 같이 정리가 가능하다.
- 트랜잭션이 커밋 되면 영속성 컨텍스트 내부에서 먼저 flush()가 호출 된다.
- 엔티티와 스냅샷을 비교하여 변경된 엔티티를 찾는다.
- 변경된 엔티티가 있으면 수정되었다고 판단하고, Update 쿼리를 생성해서 쓰기 지연 저장소로 보낸다.
- 특정 조건으로 인해 DB에 쿼리 수행을 요청한다.
- 트랜잭션이 커밋되면 정상적으로 Update가 완료된다.
지연 로딩
마지막으로 지연 로딩은 컬렉션을 호출 할 때 사용되는 기능이다.
예를 들어서, 엔티티안에 Many To One 연관 관계로 인한 구성 객체가 존재한다고 했을 때, 해당 엔티티를 호출 하면 연관 된 구성 객체까지 같이 호출 될 것이라고 예상 할 수 있다. 이러한 상황을 즉시 로딩이라고 한다.
하지만 지연 로딩은 실제로 해당 구성 객체를 호출 할 때 까지 해당 쿼리가 따로 수행되지가 않는 것을 의미한다. 즉, 호출이 되면 그제서야 호출되기 때문에 지연 로딩이라고 하는 것이다.
해당 포스팅은 인프런 김영한님의 자바 ORM 표준 JPA 프로그래밍 - 기본편, 자바 ORM 표준 JPA 책을 기반으로 작성되었습니다.
자바 ORM 표준 JPA 프로그래밍 | 김영한 - 교보문고
자바 ORM 표준 JPA 프로그래밍 | 자바 ORM 표준 JPA는 SQL 작성 없이 객체를 데이터베이스에 직접 저장할 수 있게 도와주고, 객체와 관계형 데이터베이스의 차이도 중간에서 해결해준다. 이 책은 JPA
product.kyobobook.co.kr
'Backend > JPA' 카테고리의 다른 글
| Hibernate Set<T> ClassCastException (1) | 2025.08.25 |
|---|---|
| Spring Data JPA는 왜 @Repository를 사용하지 않아도 될까? (1) | 2023.05.14 |
| JPA 상속관계 매핑 (0) | 2023.05.01 |
| JPA 연관관계 매핑의 다중성 (0) | 2023.04.28 |