
Spring Data
스프링 데이터 JPA를 알기전에 먼저 스프링 데이터부터 알아봐야 한다.
사실 스프링 데이터 JPA는 JPA에 특화 된 스프링 데이터 프로젝트의 하나이다. 실제로는 스프링 데이터 Redis, 스프링 데이터 Mongo 등등 다양한 스프링데이터들이 존재한다. 이러한 것들을 인터페이스화 하여, 공통 기능으로 간단한 쿼리를 생성해주는 것이 Spring Data이다.
Spring Data JPA
스프링 데이터에는 여러가지 메서드들이 있고, JPA에 특화된 스프링 데이터 JPA 계층구조를 잠시 살펴보자.
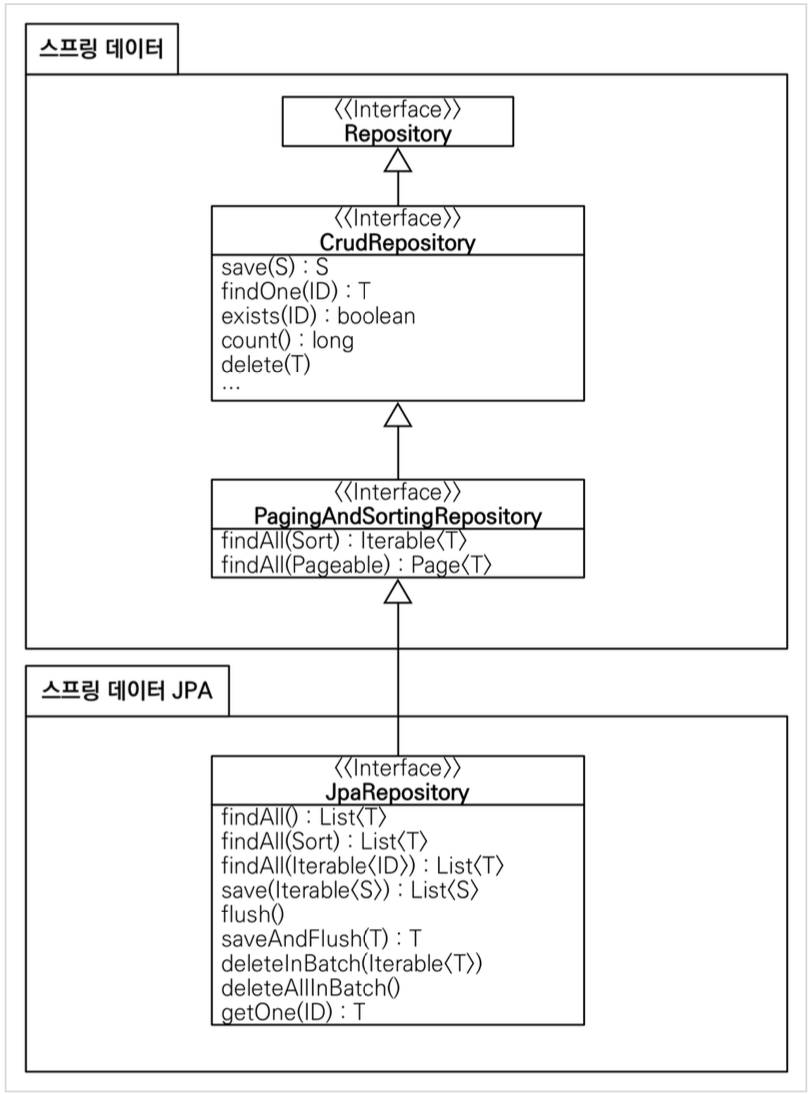
다음과 같은 구조를 하고 있다. 그런데 이상한 점은 스프링 데이터 JPA를 만들게 되면 우리는 빈으로 등록하지 않았음에도 불구하고, 스프링 데이터 JPA의 인터페이스가 빈으로 등록되어 있고, 그리고 그에 해당하는 메서드들을 사용 할 수 있는 것을 볼 수 있다.
하나씩 계층적으로 올라가보자.
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {JpaRepository를 보니 @NoRepositoryBean이라는 애노테이션이 보인다. 해당 애노테이션이 어떤 기능을 하는지 알아보자.
Annotation to exclude repository interfaces from being picked up and thus in consequence getting an instance being created. This will typically be used when providing an extended base interface for all repositories in combination with a custom repository base class to implement methods declared in that intermediate interface. In this case you typically derive your concrete repository interfaces from the intermediate one but don't want to create a Spring bean for the intermediate interface.
--
리포지토리 인터페이스가 선택되지 않도록 제외하여 결과적으로 생성되는 인스턴스를 가져오는 주석입니다. 이는 일반적으로 중간 인터페이스에서 선언된 메서드를 구현하기 위해 사용자 지정 리포지토리 기본 클래스와 함께 모든 리포지토리에 확장된 기본 인터페이스를 제공할 때 사용됩니다. 이 경우 일반적으로 중간 인터페이스에서 구체적인 리포지토리 인터페이스를 파생하지만 중간 인터페이스에 대한 Spring 빈을 생성하고 싶지는 않습니다.
설명을 봐서는 무슨 말인지 잘 이해가 되지 않는다.
혹시 몰라 가장 최상위 계층인 Repository 인터페이스까지 올라가면 다음과 같은 설명이 보인다.
Central repository marker interface. Captures the domain type to manage as well as the domain type's id type. General purpose is to hold type information as well as being able to discover interfaces that extend this one during classpath scanning for easy Spring bean creation.
--
중앙 저장소 마커 인터페이스. 관리할 도메인 유형과 도메인 유형의 id 유형을 캡처합니다. 일반적인 목적은 유형 정보를 보유하고 클래스 경로 스캐닝 중에 이를 확장하는 인터페이스를 발견하여 쉽게 Spring bean을 생성할 수 있도록 하는 것입니다.
이 부분에서 스프링 빈을 등록하도록 해주는 데 도움을 주는 것 같다.
하지만 실제 주입 된 인터페이스의 클래스를 확인해보면 다음과 같이 출력되는 것을 볼 수 있다. class com.sun.proxy.$ProxyXXX
자바의 JDK 동적 프록시를 사용한 모습을 볼 수 있다. 스프링 빈 후처리기를 통해서 중간에 주입 된 클래스가 동적 프록시를 통해서 프록시 객체가 주입 된 것인데, 그럼 실제 등록되는 구현체는 무엇일까?
스프링 데이터 JPA 구현체
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
...
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
...
}실제 구현체는 SimpleJpaRepository이다. JPA의 쿼리는 무조건 트랜잭션 내에서만 수행 될 수 있다. @Transactional 애노테이션을 통해 AOP가 적용된 트랜잭션 처리를 하고 있는 것을 볼 수 있고, @Repository 애노테이션을 사용해서 JPA 쿼리 예외 발생 시에 스프링의 예외 변환기를 통해서 예외가 변환되는 모습도 볼 수 있다.
자주사용하는 save 메서드만 따로 뽑아서 가져왔는데, Assert 인터페이스를 이용해서, 엔티티가 null일 경우에 처리하는 예외도 보이고, 엔티티가 처음 생성되는 경우 혹은 이미 존재하는 엔티티인 경우에 대해서도 체크하고 있는 것을 볼 수 있다.
해당 사실을 모르고 프로젝트를 진행하면서 커스텀 인터페이스 중 가장 최상위 인터페이스인 스프링데이터 JPA에 @Repository를 사용했었는데, 그럴 필요도 없던 부분이었다.
참고로 해당 내용은 프록시 라는 것 자체를 모른다면 이해하기가 쉽지 않습니다.
추가 내용은 프록시, 스프링 프록시 에서 확인이 가능합니다.
'Backend > JPA' 카테고리의 다른 글
| JPA 상속관계 매핑 (0) | 2023.05.01 |
|---|---|
| JPA 연관관계 매핑의 다중성 (0) | 2023.04.28 |
| 영속성 컨텍스트 (0) | 2023.04.25 |